# 0082 删除排序链表中的重复元素 II
你好啊,我是蓝莓,今天是每日一题的第 41 天。
引用力扣题目:82 删除排序链表中的重复元素 II (opens new window)
# 题目描述
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
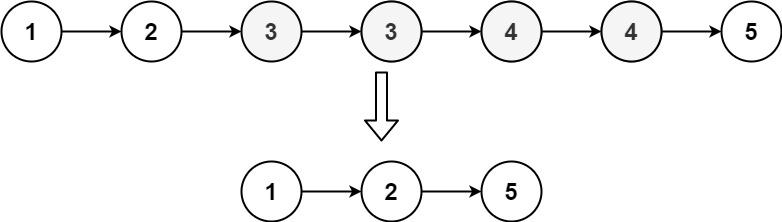
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
1
2
2
示例 2:
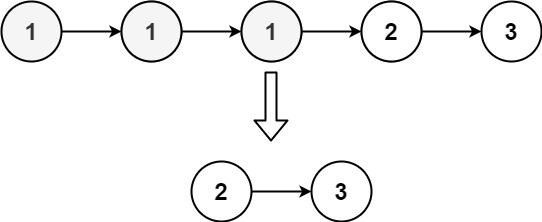
输入:head = [1,1,1,2,3]
输出:[2,3]
1
2
2
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
# 实现
思路
- 容易想到的是,我们可以使用两个指针
pre和cur,如果我们发现两者指向的节点的值是相同的,那就说明我们发现了重复元素 - 这时候我们需要将等于我们发现的这个值的所有的节点全部删掉,方法其实很简单,我们只需要继续让
cur向下继续找,找到第一个不等于当前发现的这个值的那个节点就可以了 - 随后,我们让
pre的前一个节点的next指向我们发现的第一个不等于该值的节点,那么中间的链表就从逻辑上删除了 - 但是,问题来了,我们无法访问到
pre的前一个节点,所以这时候可以再添加一个指针prePre,让它指向pre的前一个节点 - 最后,如果我们遍历的过程中,当前遍历到的节点是不重复的,那么就让每个指针都向后移动一次即可
C++ 代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
// 虚拟头结点
ListNode* dummy = new ListNode(-1, head);
if( head == nullptr ) {
return head;
}
ListNode* prePre = dummy; // 指向 cur 的前一个的前一个元素
ListNode* pre = head; // 指向 cur 的前一个元素
ListNode* cur = pre->next; // 指向链表中的第二个节点,当前正在检查的节点
while( cur != nullptr ) {
if( pre->val == cur->val ) {
// 发现重复元素
int val = cur->val;
// 将 cur 移动到当前发现的重复元素的最后一个元素的下一个节点处
while( cur != nullptr && cur->val == val ) cur = cur->next;
// 在逻辑上截断中间这组重复的元素
prePre->next = cur;
pre = cur;
// cur 若为空说明已经结束;cur 不为空则继续算法
if( cur != nullptr ) {
cur = cur->next;
} else {
break;
}
} else {
// 没有发现重复的元素 正常维护指针
prePre = pre;
pre = cur;
cur = cur->next;
}
}
return dummy->next;
}
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51